
缓存设计
缓存设计
在读多写少的服务中,可以通过缓存将一些代价较为高昂的请求结果保存,比如对数据库的读取请求或者一些复杂操作结果进行保留,实现较高的性能。因而缓存是一个比较通用但是又效果良好的手段去增强我们的服务性能。
缓存结构
缓存一般有三个对象即请求方、缓存、存储层;请求方一般是想要获取存储层的数据,但是存储层数据往往可能会涉及磁盘 io 导致请求时间开销较大,因而使用内存缓存请求结果,下次获取同样的数据先在缓存层获取再在存储层获取:
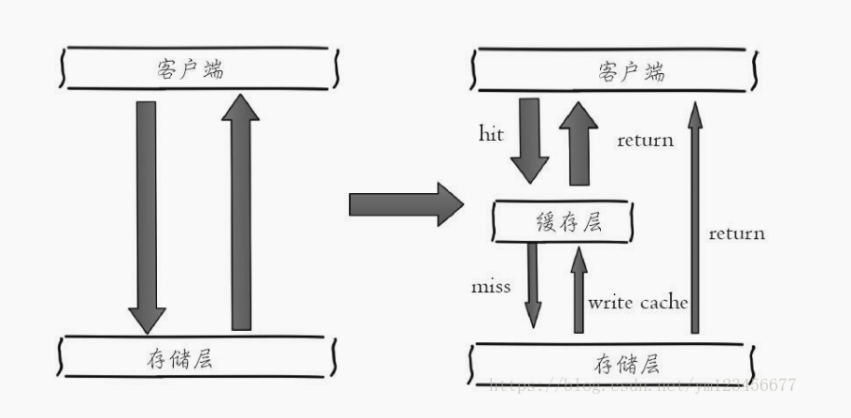
缓存优缺点
优点
- 降低响应时间,内存操作一般在 100ns 之内而涉及请求或者磁盘 io 的性能一般至少在 10ms 左右,因此使用内存缓存能够极大降低系统吞吐能力和响应时间;
- 降低后端负载,使用缓存能够极大程度降低下游负载,尤其是对于很多服务都在用的存储层而言,降低负载能够减少存储层崩溃的可能;
缺点
- 增加复杂度,最简单的增加一个缓存层会增加代码层面的复杂度,增加一个缓存中间件会增加整体系统的复杂度;
- 数据一致性问题:缓存层和存储层中间数据同步过程中会有一定的时间出现缓存数据和存储数据不一致;
虽然如此,但是缓存的效果太好,一般而言,如果同一份数据会被请求两次以上,那么增加这个数据的缓存就是值得的;
缓存设计
缓存设计一共涉及到两个部分的问题:
- 缓存更新
- 缓存命中
- 缓存失效
缓存和存储层最大区别在于缓存容量较小但是速度较快,而存储层速度慢但是容量大,所以不可能把所有数据都存储到缓存之中,那么就会有如何清理过期缓存,如何更新缓存的问题。
缓存命中
缓存是用于缓存后端服务的请求结果用的,其效果主要体现在缓存命中的时候直接返回结果,减少对后端的请求次数,降低请求时间和后端负载。缓存未命中一般会从存储层获取数据,建立缓存并且返回结果。
缓存失效
缓存容量小而存储层容量大,一般无法缓存所有的结果,因而需要设置缓存失效时间,当缓存时间到了删除缓存,减少缓存资源占用,降低资源占用,但是又不能频繁删除,一般有以下三种方式:
- LRU:按照上次访问次序排序,清理最近未使用的缓存
- LFU:按照访问次数排序,清理访问次数最低的缓存
- FIFO:一般不使用这种,按照缓存建立的先后顺序清理。
缓存更新
当存储层的数据发生变化时需要更新缓存层数据,在存储层数据更新到缓存层更新的时间内会存在一定的时间数据不一致。一般对于缓存更新的逻辑主要有三种:
- cache aside: 当写请求来的时候更新存储层,完成之后删除缓存层数据,当下一次读取数据的时候建立新的缓存。
- write through: 对数据的写直接更新到缓存,同时将缓存更新到存储层,当没有命中的时候直接更新存储。
- write Behind: 对数据的写会写到缓存,同时定时将缓存同步到存储层。
三种缓存模式
总体而言,缓存设计一共三种模式:
- Cache Aside 模式:写数据之后删除对应的缓存
- Read/Write Through 模式:缓存层管理存储层数据,应用层不会直接接触存储层
- Write Behind Cache 模式:写入直接更新缓存,之后再次读取的时候保存数据或者定时同步缓存到存储层
| 缓存模式 | 优点 | 缺点 |
|---|---|---|
| Cache Aside | 写数据发生的时候直接删除缓存,避免出现存储层写失败但是更新缓存的情况 | 并发情况下会出现脏数据 |
| Read/Write through | 应用程序不用关系存储层,所有操作都是对缓存层的操作 | 会出现当缓存层宕机数据丢失情况,没有缓存到的请求时间会增加,缓存层实现逻辑较为复杂 |
| Write Behind Cache | 直接操作缓存速度较快,且异步能够将数据批量的合并到存储层 | 数据不一致性最强,当存储层写入失败或者缓存层宕机都会导致数据不一致,更新逻辑也更加复杂,需要进行数据对比 |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 lixiande的博客!